

Hoofdstuk 6: Schatten en betrouwbaarheidsintervallen: Schatten
 Betrouwbaarheidsinterval voor het Populatiegemiddelde
Betrouwbaarheidsinterval voor het Populatiegemiddelde
Een betrouwbaarheidsinterval voor een populatiegemiddelde #\mu# is een reeks waardes gebaseerd op steekproefgegevens, die zeer aannemelijke kandidaten zijn voor de werkelijke waarde van het populatiegemiddelde.
Om een betrouwbaarheidsinterval te maken voor het populatiegemiddelde #\mu# zullen we gebruik moeten maken van de steekproef verdeling van het steekproefgemiddelde.
Vergeet niet dat het steekproefgemiddelde #\bar{X}# (ongeveer) de #N\bigg(\mu, \cfrac{\sigma}{\sqrt{n}}\,\bigg)# verdeling volgt als ten minste één van de volgende voorwaarden wordt voldaan:
- De populatie waaruit het monster is genomen is normaal verdeeld
- Het monster is groot genoeg om de centrale limietstelling toe te passen: #n\geq 30#
De breedte van een betrouwbaarheidsinterval wordt bepaald door de foutmarge.
#\phantom{0}#
Foutmarge
De foutmarge #(ME)# van een betrouwbaarheidsinterval voor het populatiegemiddelde #\mu# is de afstand vanaf het midden van het interval #\bar{X}# tot ofwel de ondergrens #L# of bovengrens #U#.
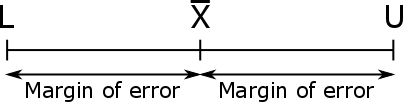
Om de foutmarge van een betrouwbaarheidsinterval voor het populatiegemiddelde #\mu# te berekenen gebruik je de volgende formule:
\[\begin{array}{rcccl}ME &=& z^* \cdot \sigma_{\bar{X}} &=& z^* \cdot \cfrac{\sigma}{\sqrt{n}}\end{array}\]
Waar #z^*# de kritische waarde is van de standaardnormale verdeling zodat:
\[\mathbb{P}(-z^* \leq Z \leq z^*) = \cfrac{C}{100}\]

Het Berekenen van z* met Statistische Software
Laat #C# het betrouwbaarheidsniveau zijn in #\%#.
Om de kritische waarde #z^*# te berekenen in Excel, gebruik je de functie NORM.INV():
\[=\text{NORM.INV}((100+C)/200, 0, 1)\]
Om de kritische waarde #z^*# te berekenen in R, gebruik je de functie qnorm():
\[\text{qnorm}(p=(100+C)/200, mean=0, sd=1,lower.tail = \text{TRUE})\]
Factoren die de Foutmarge Beïnvloeden
De foutmarge van een betrouwbaarheidsinterval voor het populatiegemiddelde #\mu# is afhankelijk van #3# factoren: het betrouwbaarheidsniveau, de standaardafwijking en de steekproefgrootte.
- Als het betrouwbaarheidsniveau toeneemt, neemt de foutmarge toe en is het betrouwbaarheidsinterval breder.
- Als de populatiestandaardafwijking toeneemt, neemt de foutmarge toe en wordt het betrouwbaarheidsinterval breder.
- Als de steekproefgrootte toeneemt, neemt de foutmarge af en wordt de betrouwbaarheidsinterval smaller.
Een onderzoeker selecteert willekeurig #140# mannen uit deze leeftijdsgroep en vindt een gemiddelde bloeddruk van #\bar{X}=127.01#.
Bereken de foutmarge van het #93\%# betrouwbaarheidsinterval voor het populatiegemiddelde #\mu#. Rond je antwoord af op #3# decimalen.
#ME=1.531#
Er is een aantal verschillende manieren waarop we de foutmarge kunnen berekenen. Klik op een van de panelen om naar een specifieke oplossing te gaan.
De foutmarge van een betrouwbaarheidsinterval voor een populatiegemiddelde #\mu# wordt berekend met de volgende formule:
\[ME=z^* \cdot \sigma_{\bar{X}}\]
Aangezien de populatie waaruit de steekproef wordt getrokken normaal verdeeld is, weten we dat de steekproefverdeling van het steekproefgemiddelde de #N(\mu, \sigma / \sqrt{n})# verdeling is.
Bepaal de standaardafwijking van het gemiddelde #\sigma_{\bar{X}}#:
\[\sigma_{\bar{X}}=\cfrac{\sigma}{\sqrt{n}}=\cfrac{10}{\sqrt{140}}=0.84515\]
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in Excel te berekenen, gebruik je de volgende functie:
NORM.INV(probability, mean, standard_dev)
- probability: Een kans die overeenkomt met de normaalverdeling.
- mean: Het gemiddelde van de verdeling.
- standard_dev: De standaardafwijking van de verdeling.
We hebben hier #C=93#. Dus om #z^*# te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.93#, moet je het volgende commando uitvoeren:
\[\begin{array}{c}
=\text{NORM.INV}((100+C)/200, 0, 1)\\
\downarrow\\
=\text{NORM.INV}(193/200, 0, 1)
\end{array}\]
Dit geeft:
\[z^* = 1.81191\]
Met deze informatie kan de foutmarge worden berekend als:
\[ME=z^* \cdot \sigma_{\bar{X}} = 1.81191 \cdot 0.84515 = 1.531\]
De foutmarge van een betrouwbaarheidsinterval voor het populatiegemiddelde #\mu# wordt berekend met de volgende formule:
\[ME=z^* \cdot \sigma_{\bar{X}}\]
Aangezien de populatie waaruit de steekproef wordt getrokken normaal verdeeld is, weten we dat de steekproefverdeling van het steekproefgemiddelde de #N(\mu, \sigma / \sqrt{n})# verdeling is.
Bepaal de standaardafwijking van het gemiddelde #\sigma_{\bar{X}}#:
\[\sigma_{\bar{X}}=\cfrac{\sigma}{\sqrt{n}}=\cfrac{10}{\sqrt{140}}=0.84515\]
Voor een gegeven betrouwbaarheidsinterval #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# te berekenen in R, maak je gebruik van de volgende functie:
qnorm(p, mean, sd, lower.tail)
- p: Een kans die overeenkomt met de normaalverdeling.
- mean: Het gemiddelde van de verdeling.
- sd: De standaardafwijking van de verdeling.
- lower.tail: Indien TRUE (standaard), is de kans #\mathbb{P}(X \leq x)#, anders #\mathbb{P}(X \gt x)#.
We hebben hier #C=93#. Dus om #z^*#te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.93#, voer je het volgende commando uit:
\[\begin{array}{c}
\text{qnorm}(p = (100+C)/200, mean = 0, sd = 1, lower.tail = \text{TRUE})\\
\downarrow\\
\text{qnorm}(p =193/200, mean = 0, sd = 1, lower.tail = \text{TRUE})
\end{array}\]
Dit geeft:
\[z^* = 1.81191\]
Met deze informatie kan de foutmarge berekend worden als:
\[ME=z^* \cdot \sigma_{\bar{X}} = 1.81191 \cdot 0.84515 = 1.531\]
#\phantom{0}#
Algemene Formule voor een Betrouwbaarheidsinterval voor een Populatiegemiddelde
Aannemend dat de steekproef verdeling van het steekproefgemiddelde (ongeveer) normaal is, is de algemene formule voor het berekenen van een #C\%# betrouwbaarheidsinterval voor het populatiegemiddelde #\mu#, gebaseerd op een aselecte steekproef van omvang #n#:
\[CI_{\mu}=\bigg(\bar{X} - z^*\cdot \cfrac{\sigma}{\sqrt{n}},\,\,\,\, \bar{X} + z^*\cdot \cfrac{\sigma}{\sqrt{n}} \bigg)\]
Stel dat de standaardafwijking in gewicht voor een enkele munt van één euro #\sigma=0.0599# is.
Construeer een betrouwbaarheidsinterval van #97\%# voor het populatiegemiddelde #\mu#. Rond je antwoorden af op #3# decimalen.
Er is een aantal verschillende manieren waarop we het betrouwbaarheidsinterval kunnen berekenen. Klik op een van de panelen om naar een specifieke oplossing te gaan.
Een steekproef van grootte #n=1000# wordt groot genoeg geacht om de Centrale Limietstelling toe te passen.
Dit betekent dat, hoewel de steekproef in kwestie afkomstig is uit een populatie met een onbekende verdeling, de steekproefverdeling van het steekproefgemiddelde ongeveer normaal is.
Ervan uitgaande dat de steekproefverdeling van het steekproefgemiddelde (ongeveer) normaal is, is de algemene formule voor het berekenen van een #C\%\, CI# voor een populatiegemiddelde #\mu#, gebasseerd op een willekeurige steekproef van grootte #n#:
\[CI_{\mu}=\bigg(\bar{X} - z^*\cdot \cfrac{\sigma}{\sqrt{n}},\,\,\,\, \bar{X} + z^*\cdot \cfrac{\sigma}{\sqrt{n}} \bigg)\]
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in Excel te berekenen, gebruik je de volgende functie:
NORM.INV(probability, mean, standard_dev)
- probability: Een kans die overeenkomt met de normaalverdeling.
- mean: Het gemiddelde van de verdeling.
- standard_dev: De standaardafwijking van de verdeling.
We hebben hier #C=97#. Dus om #z^*# te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.97#, voer je het volgende commando uit:
\[\begin{array}{c}
=\text{NORM.INV}((100+C)/200, 0, 1)\\
\downarrow\\
=\text{NORM.INV}(197/200, 0, 1)
\end{array}\]
Dit geeft:
\[z^* = 2.17009\]
Bereken de ondergrens #L# van het betrouwbaarheidsinterval:
\[L = \bar{X} - z^* \cdot \cfrac{\sigma}{\sqrt{n}} = 2.160 - 2.17009 \cdot \cfrac{0.0599}{\sqrt{1000}}=2.156\]
Bereken de bovengrens #U# van het betrouwbaarheidsinterval:
\[U = \bar{X} + z^* \cdot \cfrac{\sigma}{\sqrt{n}} = 2.160 + 2.17009 \cdot \cfrac{0.0599}{\sqrt{1000}}=2.164\]
Dus het #97\%# betrouwbaarheidsinterval van het populatiegemiddelde #\mu# is:
\[CI_{\mu,\,97\%}=(2.156,\,\,\, 2.164)\]
Een steekproefgrootte #n=1000# wordt groot genoeg geacht om de Centrale Limietstelling toe te passen.
Dit betekent dat, hoewel de steekproef in kwestie afkomstig is uit een populatie met een onbekende verdeling, de steekproefverdeling van het steekproefgemiddelde ongeveer normaal is.
Ervan uitgaande dat de steekproefverdeling van het steekproefgemiddelde (ongeveer) normaal is, is de algemene formule voor het berekenen van een #C\%\, CI# voor een populatiegemiddelde #\mu#, gebaseerd op een willekeurige steekproef van grootte #n#:
\[CI_{\mu}=\bigg(\bar{X} - z^*\cdot \cfrac{\sigma}{\sqrt{n}},\,\,\,\, \bar{X} + z^*\cdot \cfrac{\sigma}{\sqrt{n}} \bigg)\]
Voor een gegeven betrouwbaardheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in R te berekenen, gebruik je de volgende functie:
qnorm(p, mean, sd, lower.tail)
- p: Een kans die overeenkomt met de normaalverdeling.
- mean: Het gemiddelde van de verdeling.
- sd: De standaardafwijking van de verdeling.
- lower.tail: Indien TRUE (standaard), is de kans #\mathbb{P}(X \leq x)#, anders #\mathbb{P}(X \gt x)#.
We hebben hier #C=97#. Dus om #z^*#te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.97#, voer je het volgende commando uit:
\[\begin{array}{c}
\text{qnorm}(p = (100+C)/200, mean = 0, sd = 1, lower.tail = \text{TRUE})\\
\downarrow\\
\text{qnorm}(p =197/200, mean = 0, sd = 1, lower.tail = \text{TRUE})
\end{array}\]
Dit geeft:
\[z^* = 2.17009\]
Bereken de ondergrens #L# van het betrouwbaarheidsinterval:
\[L = \bar{X} - z^* \cdot \cfrac{\sigma}{\sqrt{n}} = 2.160 - 2.17009 \cdot \cfrac{0.0599}{\sqrt{1000}}=2.156\]
Bereken de bovengrens #U# van het betrouwbaarheidsinterval:
\[U = \bar{X} + z^* \cdot \cfrac{\sigma}{\sqrt{n}} = 2.160 + 2.17009 \cdot \cfrac{0.0599}{\sqrt{1000}}=2.164\]
Dus het #97\%# betrouwbaarheidsinterval voor het populatiegemiddelde #\mu# is:
\[CI_{\mu,\,97\%}=(2.156,\,\,\, 2.164)\]
#\phantom{0}#
Het Beheersen van de Foutmarge
Stel dat je wilt dat de foutmarge voor een #C\%# betrouwbaarheidsinterval voor het populatiegemiddelde #\mu# niet groter is dan #k#.
Dan moet de minimale steekproefomvang
\[n=\Big(\cfrac{z^* \cdot \sigma}{k}\Big)^2,\]
zijn, omhoog afgerond naar het volgende gehele getal.
Als de onderzoeker wil dat de foutmarge van het betrouwbaarheidsinterval van #96\%# voor het populatiegemiddelde #\mu# niet groter is dan #1#, wat is dan de minimale steekproefgrootte die hij nodig heeft?
#n \geq 1688#
Er is een aantal verschillende manieren waarop we de minimum steekproefgrootte kunnen berekenen. Klik op een van de panelen om een specifieke oplossing te kiezen.
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling, de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in Excel te berekenen, gebruik je de volgende functie:
NORM.INV(probability, mean, standard_dev)
- probability: Een kans die overeenkomt met de normale verdeling.
- mean: Het gemiddelde van de verdeling.
- standard_dev: De standaardafwijking van de verdeling.
We hebben hier #C=96#. Dus om #z^*# te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.96#, voer je het volgende commando uit:
\[\begin{array}{c}
=\text{NORM.INV}((100+C)/200, 0, 1)\\
\downarrow\\
=\text{NORM.INV}(196/200, 0, 1)
\end{array}\]
Dit geeft:
\[z^* = 2.05375\]
Met deze informatie kan de minimale steekproefgrootte worden berekend:
\[n=\Big(\cfrac{z^* \cdot \sigma}{k}\Big)^2=\Big(\cfrac{2.05375 \cdot 20}{1}\Big)^2=1687.1538\]
Als je deze waarde naar boven afrondt, krijg je #n=1688#.
Dus om een foutmarge te krijgen die niet groter is dan #1#, heb je een steekproefgrootte nodig van ten minste #1688#.
Voor een gegeven betrouwbaarheidsniveau #C#, is de kritische waarde #z^*# van de standaard normale verdeling, de waarde zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=\cfrac{C}{100}#.
Om deze kritische waarde #z^*# in R te berekenen, gebruik je de volgende functie:
qnorm(p, mean, sd, lower.tail)
- p: Een kans die overeenkomt met de normale verdeling.
- mean: Het gemiddelde van de verdeling.
- sd: De standaardafwijking van de verdeling.
- lower.tail: Indien TRUE (standaard), is de kans #\mathbb{P}(X \leq x)#, anders #\mathbb{P}(X \gt x)#.
We hebben hier #C=96#. Dus om #z^*#te berekenen zodanig dat #\mathbb{P}(-z^* \leq Z \leq z^*)=0.96#, voer je het volgende commando uit:
\[\begin{array}{c}
\text{qnorm}(p = (100+C)/200, mean = 0, sd = 1, lower.tail = \text{TRUE})\\
\downarrow\\
\text{qnorm}(p =196/200, mean = 0, sd = 1, lower.tail = \text{TRUE})
\end{array}\]
Dit geeft:
\[z^* = 2.05375\]
Met deze informatie kan de minimale steekproefgrootte worden berekend:
\[n=\Big(\cfrac{z^* \cdot \sigma}{k}\Big)^2=\Big(\cfrac{2.05375 \cdot 20}{1}\Big)^2=1687.1538\]
Als je deze waarde naar boven afrondt, krijg je #n=1688#.
Dus om een foutmarge te krijgen die niet groter is dan #1#, heb je een steekproefgrootte nodig van ten minste #1688#.


