

Hoofdstuk 7: Hypothese toetsen: Introductie in Hypothese Toetsen (Kritiek Gebied benadering)
 Onderscheidend Vermogen
Onderscheidend Vermogen
Onderscheidend Vermogen
Het Onderscheidend Vermogen van een toets is de kans dat de nulhypothese wordt verworpen wanneer het onjuist is.
\[\text{Vermogen} = \mathbb{P}(\text{verwerp }H_0\,|\,H_0 \text{ is onjuist}) = 1 - \mathbb{P}(\text{Type II fout}) = 1 - \beta\]
Onderscheidend vermogen kan worden gezien als de gevoeligheid van de hypothese toets.
#\phantom{0}#
Idealiter wil je een hoog vermogen om praktisch significante effecten te detecteren, maar een laag vermogen voor het detecteren van effecten die geen praktische betekenis hebben. Hoog vermogen kan worden bereikt door het gebruik van de meest krachtige statistische procedure beschikbaar is, en vervolgens een voldoende grote steekproefomvang kiezen.
Onderzoekers kiezen over het algemeen voor een steekproef grootte voor hun onderzoek gebaseerd op het doel om een gewenst vermogen voor de detectie van een bepaald effect grootte te bereiken. Bijvoorbeeld, een onderzoeker wilt ten minste #75\%# Vermogen om te detecteren dat het ware gemiddelde meer dan #2# eenheden groter is dan het veronderstelde gemiddelde #\mu_0#.
#\phantom{0}#
Vermogen Berekening voor een Z-toets voor één steekproef met statistische software
Het Vermogen van een hypothese toets kan worden berekend in een Excel of R.
Overweeg een linkszijdige toets van de nulhypothese #H_0: \mu \geq \mu_0# tegen de alternatieve hypothese #H_a: \mu \lt \mu_0# op een significantieniveau #\alpha#.
Stel dat de werkelijke waarde van het bevolkingsgemiddelde #\mu#, #\mu_1# is waar #\mu_1 \lt \mu_0#. Dan kunnen we het vermogen van deze toets berekenen door de volgende twee stappen in te vullen:
1. Bereken hoe klein #\bar{X}# moet zijn om te veroorzaken dat #H_0# wordt verworpen bij een significantie niveau van #\alpha#. Noem deze waarde #Q# :
Excel
\[Q = \mu_0 + \text{NORM.INV}(\alpha, 0, 1) \cdot \cfrac{\sigma}{\sqrt{n}}\]
R
\[Q = \mu_0 + \text{qnorm}(\alpha, 0, 1) \cdot \cfrac{\sigma}{\sqrt{n}}\]
2. Bereken het overeenkomstige vermogen:
Excel
\[\text{Power}=\text{NORM.DIST}(Q, \mu_1, \cfrac{\sigma}{\sqrt{n}}, 1)\]
R
\[\text{Power}=\text{pnorm}(Q, \mu_1, \cfrac{\sigma}{\sqrt{n}}, \text{TRUE})\]

#\phantom{0}#
Overweeg een rechtszijdige toets van de nulhypothese #H_0: \mu \leq \mu_0# tegen de alternatieve hypothese #H_a: \mu \gt \mu_0# op een significantieniveau #\alpha#.
Stel dat de werkelijke waarde van het bevolkingsgemiddelde #\mu#, #\mu_1# is waar #\mu_1 \gt \mu_0#. Dan kunnen we het vermogen van deze toets berekenen door de volgende twee stappen in te vullen:
1. Bereken hoe groot #\bar{X}# moet zijn om te veroorzaken #H_0# bij een significantie niveau worden afgewezen #\alpha#. Noem deze waarde #Q# :
uitmunten
\[Q = \mu_0 + \text{NORM.INV}(1-\alpha, 0, 1) \cdot \cfrac{\sigma}{\sqrt{n}}\]
R
\[Q = \mu_0 + \text{qnorm}(1 - \alpha, 0, 1) \cdot \cfrac{\sigma}{\sqrt{n}}\]
2. Bereken het overeenkomstige vermogen:
uitmunten
\[\text{Power}=1-\text{NORM.DIST}(Q, \mu_1, \cfrac{\sigma}{\sqrt{n}}, 1)\]
R
\[\text{Power}=\text{pnorm}(Q, \mu_1, \cfrac{\sigma}{\sqrt{n}}, \text{FALSE})\]

Ze verkrijgt een willekeurige steekproef ter grootte van #n = 51# uit een populatie met onbekend gemiddelde #\mu# en standaardafwijking #\sigma = 8#.
Stel dat de werkelijke waarde van #\mu# #23# is.
Wat is het onderscheidingsvermogen van de test? Rond je antwoord af op #3# decimalen.
Er zijn een aantal verschillende manieren waarop we het Onderscheidingsvermogen van de test kunnen berekenen. Klik op een van de panelen om naar een specifieke oplossing te gaan.
Laat #\mu_1# het werkelijke populatiegemiddelde noteren, dan #\mu_1 = 23#.
Bereken hoe klein #\bar{X}# moet zijn om ervoor te zorgen dat #H_0# wordt verworpen bij het #\alpha = 0.10# significantieniveau:
\[\begin{array}{rcl}
Q &=& \mu_0 + \text{NORM.INV}(\alpha, 0, 1) \cdot \cfrac{\sigma}{\sqrt{n}}\\
&=& 25 + \text{NORM.INV}(0.10, 0, 1) \cdot \cfrac{8}{\sqrt{51}}\\
&=& 23.56438
\end{array}\]
Bereken het Onderscheidingsvermogen:
\[\begin{array}{rcl}
\text{Onderscheidingsvermogen} &=& \text{NORM.DIST}(Q, \mu_1, \cfrac{\sigma}{\sqrt{n}}, 1)\\
&=& \text{NORM.DIST}(23.56438, 23, \cfrac{8}{\sqrt{51}}, 1)\\
&=& 0.693
\end{array}\]
Laat #\mu_1# het werkelijke populatiegemiddelde noteren, dan #\mu_1 = 23#.
Bereken hoe klein #\bar{X}# moet zijn om ervoor te zorgen dat #H_0# wordt verworpen bij het #\alpha = 0.10# significantieniveau:
\[\begin{array}{rcl}
Q &=& \mu_0 + \text{qnorm}(\alpha, 0, 1) \cdot \cfrac{\sigma}{\sqrt{n}}\\
&=& 25 + \text{qnorm}(0.10, 0, 1) \cdot \cfrac{8}{\sqrt{51}}\\
&=& 23.56438
\end{array}\]
Bereken het Onderscheidingsvermogen:
\[\begin{array}{rcl}
\text{Onderscheidingsvermogen} &=& \text{pnorm}(Q, \mu_1, \cfrac{\sigma}{\sqrt{n}}, \text{WAAR})\\
&=& \text{pnorm}(23.56438, 23, \cfrac{8}{\sqrt{51}}, \text{WAAR})\\
&=& 0.693
\end{array}\]
#\phantom{0}#
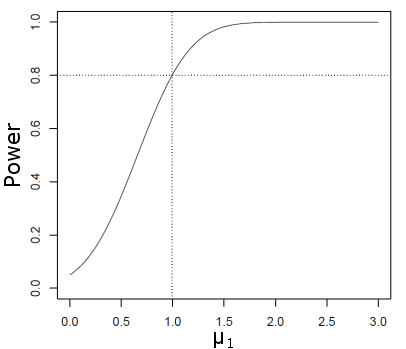
Vermogenskromme
Vaak wordt een Vermogenskromme gebruikt om de relatie tussen vermogen en effectgrootte voor een bepaalde steekproefomvang, significantieniveau of standaarddeviatie te onderzoeken.
Bijvoorbeeld, hieronder is de Vermogenskromme voor de toets #H_0: \mu \leq 0# tegen #H_a: \mu \gt 0# weergegeven op de #\alpha=0.05# significantieniveau, wanneer #\sigma = 4# en #n=100#. Hier, #\mu_1# geeft de werkelijke waarde van het bevolkingsgemiddelde #\mu#.
Merk op dat voor een effect grootte van #0#, het vermogen altijd gelijk is aan het significantieniveau (in dit geval, #0.05# ).
Het vermogen neemt gestaag toe als de effect grootte groter wordt, en bereikt het doel Vermogen van #0.8# wanneer deeffect grootte gelijk is aan #1#.
Het vermogen vlakt daarna af in de richting van het maximale vermogen van #1.0# voor grotere effect groottes.
Het wijzigen van #n, \alpha,# of #\sigma# zal de vorm van de Vermogenskromme veranderen. Voor een gegeven effect grootte, zal het vermogen groter zijn als:
- De steekproefomvang #n# toeneemt.
- Het significantieniveau #\alpha# toeneemt.
- De populatiestandaarddeviatie #\sigma# afneemt.

omptest.org als je een OMPT examen moet maken.

