

Hoofdstuk 10: ANOVA: One-Way Analysis of Variance (final) *
 Enkelvoudige variantieanalyse: post hoc tests
Enkelvoudige variantieanalyse: post hoc tests
Bedenk dat wanneer we een variantieanalyse (ANOVA) gebruiken om de verschillen tussen drie of meer populatiegemiddelden te onderzoeken, we de volgende hypothesen testen:
\[\begin{array}{rcl}
H_0&:& \text{Alle populatiegemiddelden zijn gelijk.}\\\\
H_a&:& \text{Niet alle populatiemiddelen zijn gelijk.}
\end{array}\]
Zoals je kunt zien stelt de alternatieve hypothese alleen dat er een verschil bestaat tussen populatiegemiddelden, maar specificeert ze niet welke gemiddelden verschillend zouden moeten zijn. Als de nulhypothese van gelijke gemiddelden wordt verworpen, zijn dus aanvullende tests nodig om te bepalen welke paren van gemiddelden verschillend zijn.
Als we de verschillen tussen elk paar van gemiddelden afzonderlijk willen onderzoeken, krijgen we onvermijdelijk te maken met kanskapitalisatie. Om te voorkomen dat dit probleem optreedt, kan een speciaal ontworpen post hoc test worden uitgevoerd.
Post hoc-analyse
Een post hoc test is een aanvullende test die wordt uitgevoerd nadat de nulhypothese van een ANOVA is verworpen, om te bepalen welke verschillen in populatiegemiddelde significant zijn en welke niet.
Post hoc tests zijn ontworpen om gelijktijdig alle paren van gemiddelden te vergelijken, terwijl tegelijkertijd de family-wise error rate (vrij vertaald: familie-gecorrigeerde foutmarge) wordt gecontroleerd, dat wil zeggen, de totale kans op het maken van een Type I-fout bij het uitvoeren van meerdere tests. Dit wordt gedaan door het significantieniveau van elke individuele test te corrigeren, zodat voor alle paren de totale kans op minstens één Type I-fout gelijk blijft aan #\alpha#.
Voor elk paar populaties (#i#, #j#) worden de volgende hypothesen getest:
\[\begin{array}{rcl}
H_0&:& \mu_i = \mu_j \text{ (De populatiegemiddelden zijn gelijk.)}\\\\
H_a&:&\mu_i \neq \mu_j \text{ (De populatiegemiddelden zijn niet gelijk.)}
\end{array}\]
In de praktijk kunnen de berekeningen van een post hoc test het beste worden overgelaten aan statistische software, die over het algemeen een samenvattende tabel van de resultaten zal produceren, inclusief de #p#-waarde van de tests, evenals betrouwbaarheidsintervallen voor de verschillen in gemiddelde.
Als de #p#-waarde kleiner is dan of gelijk is aan #\alpha#, of als het betrouwbaarheidsinterval van het verschil in gemiddelde #0# niet omvat, kunnen we concluderen dat de populatiegemiddelden verschillend zijn.
Voor elk type ANOVA zijn er een groot aantal post hoc tests beschikbaar. In de context van een enkelvoudige ANOVA raden we je aan te kiezen tussen de volgende twee alternatieven:
- Als aan de aanname van gelijke populatievarianties (homoscedasticiteit) is voldaan, wordt de methode van Tukey-Kramer (Engels: Tukey-Kramer method for Honestly Significant Differences, HSD) aanbevolen.
- Als de aanname van gelijke populatievarianties wordt geschonden, wordt de Games-Howell post hoc test aanbevolen.
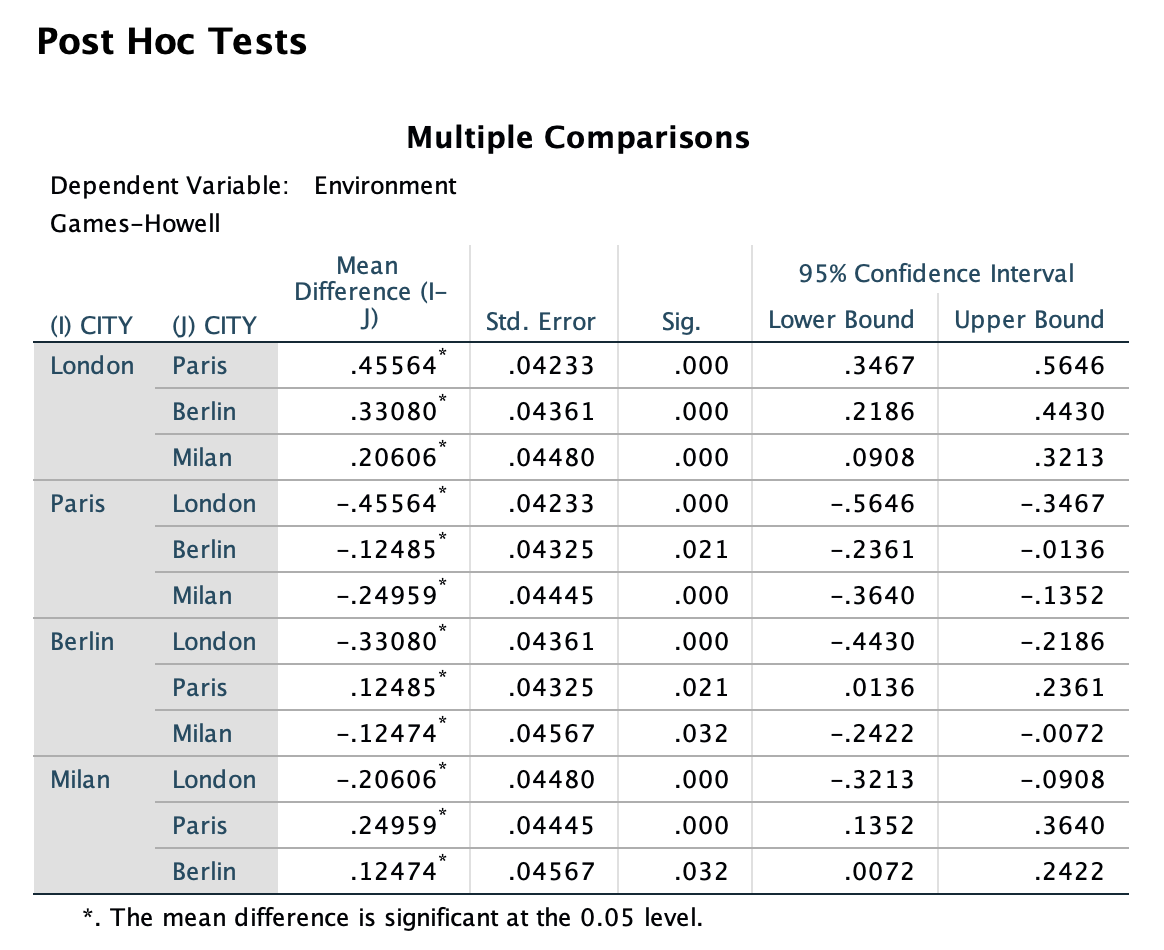
Op basis van deze resultaten concluderen we dat alle stedenparen, met uitzondering van Parijs-Berlijn (#p=0.021#) en Berlijn-Milaan (#p=0.032#), significant van elkaar verschillen op een significantieniveau van #0.01#.
Een voorbeeld van de resultaten van een post hoc test in #\mathrm{R}#, op basis van de methode van Tukey, vind je hieronder.
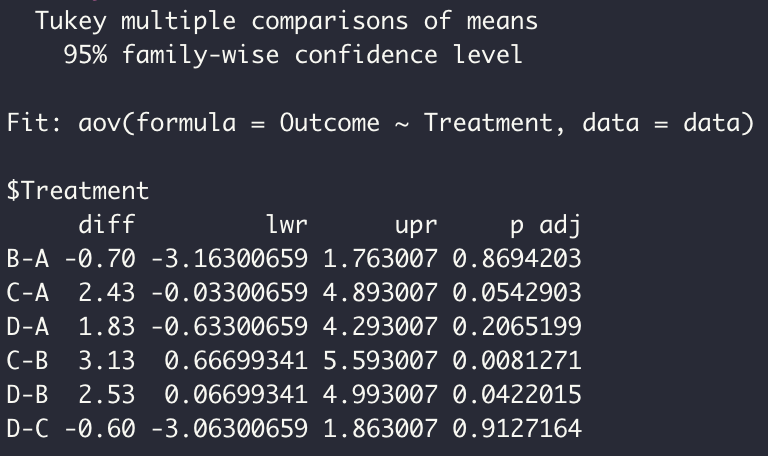
Op basis van deze resultaten concluderen we dat alleen de gemiddelden van behandelingen C en B ( #p=0.008# ) significant van elkaar verschillen op een significantieniveau van #0.01#.

omptest.org als je een OMPT examen moet maken.

